Matrix factorization (MF) recommender trained on the Last.fm LFM-1b dataset
(1+ billion listening events, ~120K users, ~5.6M tracks). Both training and inference
are implemented across CPU and GPU paths to measure performance gains on a real ML
workload, given the constraints of my local machine.
Schedl, M. (2016). The LFM-1b Dataset for Music Retrieval and Recommendation. Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR 2016), New York, USA, April 2016.
Given ~120K users and ~5.6M unique tracks, materializing the full user-track ratings matrix
is infeasible (~670 billion entries, of which only a small fraction carry signal). Matrix factorization
instead approximates this matrix as the product of two compact (low rank) embedding matrices,
U (users × k) and S (tracks × k), which explain observed
listening behavior, and can be used to generalize to unobserved behavior (inference time).
For training, Alternating Least Squares (ALS) is used on implicit feedback (play counts converted
to a binary preference and a logarithmic confidence weight). Both the user step and item
step are embarrassingly parallel, a natural fit for GPU batched solves, and the primary reason
I chose a MF model for this project. Inference consists of a simple dot product and top-K sort, which
is implemented through a single large SGEMM plus a parallel top-K in the GPU accelerated path,
exactly the dense linear algebra cuBLAS is built for.
Approach
Low-rank factorization. Replace the sparse 120K × 5.6M ratings matrix
with two dense embedding matrices U ∈ ℝ120K×64 and S ∈ ℝ5.6M×64.
The predicted preference for user u on track i is simply the dot product of the respective rows.
ALS with implicit feedback. Each ALS sub-problem has a closed-form solution:
Uu = (STCuS + λI)−1STCupu.
Loss decreases monotonically and convergence is guaranteed.
The computational trick. STCuS decomposes into
a constant term STS (computed once per iteration) plus a sparse correction
over only the tracks user u actually listened to - reducing each user update
from O(n) to O(nu), where nu is typically 50–500 instead of all
n = 5.6M tracks.
Batched GPU solves. The per-user k×k linear systems are batched
into cublasSgetrfBatched + cublasSgetrsBatched calls
(chunked across users to stay within GPU memory), saturating the GPU's arithmetic units.
Inference at scale. A batch of 1000 concurrent requests becomes one
cuBLAS SGEMM of shape (1000 × 64) · (64 × 5.6M) - about 720 billion floating-point operations -
completed in milliseconds, followed by a parallel top-K argpartition kernel. A Python
script is used to simulate request/response model, rather than a full backend implementation.
CPU training baseline (NumPy/SciPy). Single-threaded ALS reference - establishes correctness and a wall-clock baseline.
GPU training (CUDA + cuBLAS). Batched LU factorization and solve on the GPU for both the user step and the item step. Binary embedding matrices written for inference.
CPU inference baseline (C++ + OpenBLAS + OpenMP). Parameterizable threading - serves as the non-HPC and HPC-CPU reference for the latency comparison.
GPU inference (CUDA + cuBLAS). Embeddings loaded once into GPU memory, concurrent requests served via SGEMM + parallel top-K kernel.
Results
The CPU baseline (single-threaded NumPy/SciPy or OpenBLAS+OpenMP) and the GPU build
(CUDA + cuBLAS) are run on the same preprocessed data and benchmarked end-to-end -
training wall-clock, request latency under load, and tail-latency scaling.
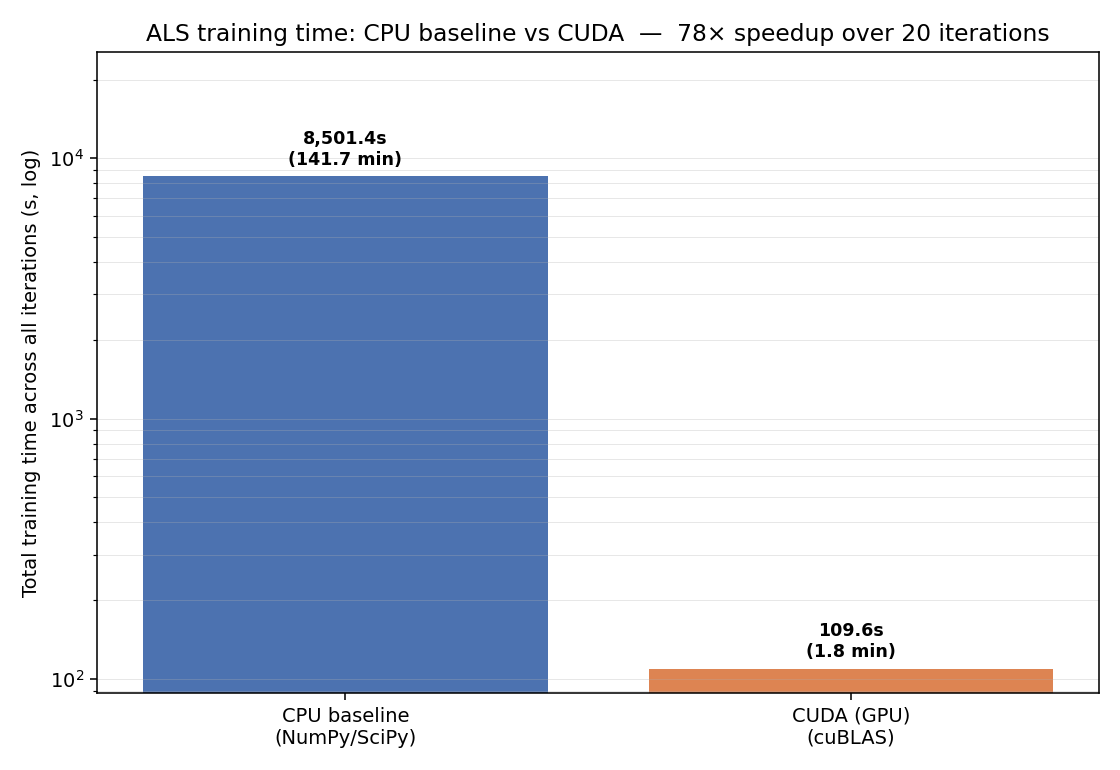
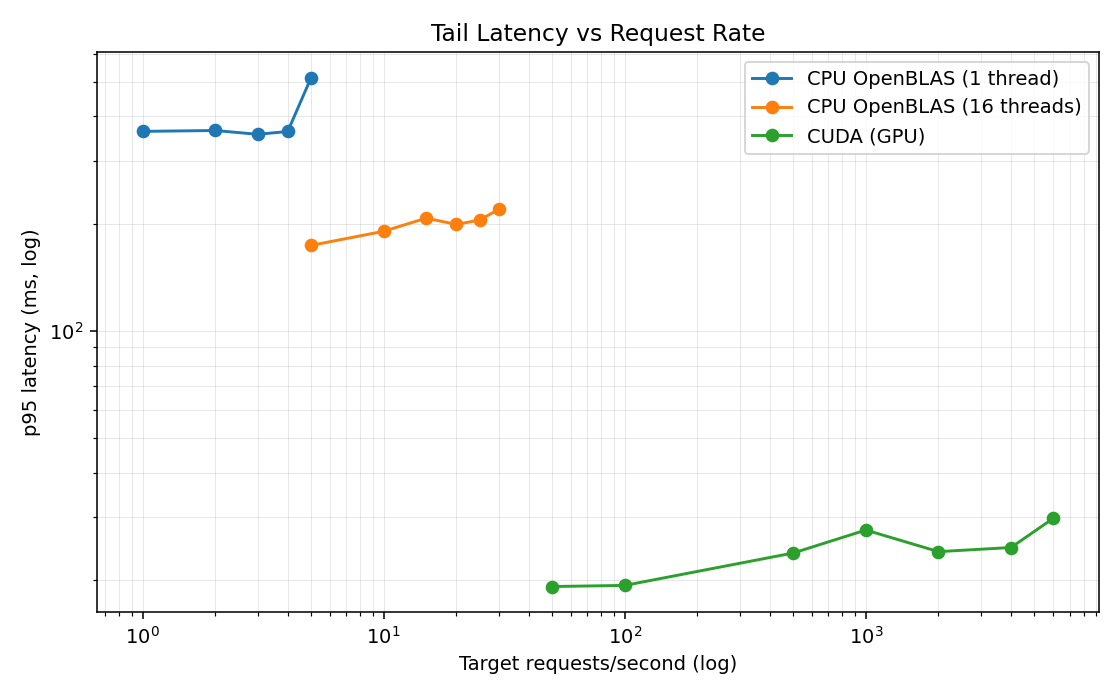
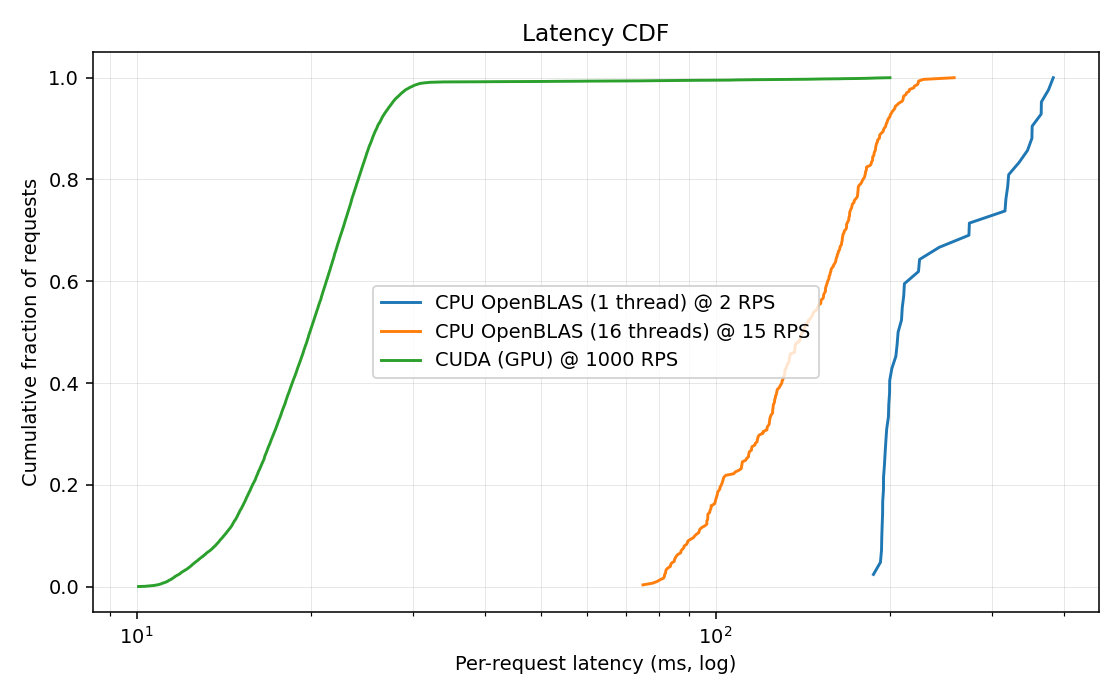
End-to-end ALS training wall-clock - GPU vs CPU baselines.p95 inference latency as concurrent request rate ramps up.Per-request latency distribution across CPU single-threaded, CPU multi-threaded, and GPU.